Web scraping is one of the most common data collection methods, but its legality is still a much-debated topic. So, is web scraping legal? While the answer is not so straightforward, in this post we take a look at what web scraping is, its legal implications and best practices. 👀 Let’s dive in!

What is web scraping?
Web scraping (or data scraping): what it is and how it works
Web scraping involves the extraction of data from a website, the information collected is then exported in a format that is more useful for the user.
In more technical terms, the scraper uses the HTML, CSS or JavaScript code/elements of a web page and extracts all the data present or selects some specific information of value. In fact, web scraping allows you to target specific information (i.e. scrape an Amazon page for prices but not for product reviews).
🔍 In general, web scraping is done via dedicated and automated tools that work faster than doing web scraping manually.
Examples of web scraping
While web scraping involves developers as it can get quite technical, it is a valuable tool for researchers, journalists, academics, and more.
Web scraping can be used for:
- Market research (i.e. competitor analysis on product data from e-commerce sites such as Amazon or eBay);
- Price monitoring (i.e. stock prices);
- News monitoring;
- Gathering store locators, sports stats, etc.
Is web scraping legal?
The legality of web scraping
Just like most people who research this topic, you might be wondering: is scraping data legal? Don’t get too enthusiastic, unfortunately, the entire subject remains a gray area.
Web scraping is generally allowed where:
- the extracted data is publicly available data; and
- the information collected isn’t protected by a login.
In general, responsible web scraping requires you to be cautious about applicable Terms of Service, copyrighted data and personal data (as personal data is typically protected by privacy laws).
🔍 Take a look at our detailed guide on what is considered personal information across major privacy laws.
Data scraping under privacy laws
The major privacy laws to date in the EU (the GDPR) or in the US (the CPRA) aim at protecting user personal data and setting a framework for how this data can be used.
They do not refer to web scraping or state that it is illegal. However, they regulate the collection of personal data by businesses and what they can do with it. In brief – because yes, the law is much more complicated than that! – it usually involves:
- receiving explicit consent from data subjects;
- gathering personal data only for specific purposes;
- informing users of what data is collected, how, and their rights.
🔍 In short, if your web scraping activities involve scraping personal information, you must make sure you are compliant with data privacy laws.
💡 Not sure what privacy laws actually apply to you?
Garante guidance
Please note that while this guidance comes from the Italian Garante, the suggestions are useful for all countries.
In May 2024, the Garante published a guidance document that contains instructions for defending personal data published online by public and private entities as data controllers from web scraping in the context of generative AI training. The Garante suggests a number of concrete measures to be adopted including:
- the creation of reserved areas, accessible only upon registration, so as to remove data from public availability;
- the inclusion of anti-scraping clauses in the terms of service of websites or online platforms;
- the monitoring of traffic to web pages, so as to identify any abnormal flows of incoming and outgoing data (an example of an appropriate measure to take is limiting network traffic and the number of access requests by selecting only those from certain IP addresses); and
- the implementation of specific measures against bots using some technological solutions (e.g.: intervening on the robots.txt file; including CAPTCHA checks; making periodic modifications of HTML markup; incorporating content or data intended to avoid scraping activities within multimedia items such as images).
Through the adoption of these actions, although they are not exhaustive in either method or result, operators of websites and online platforms may contain the effects of scraping aimed at training generative artificial intelligence algorithms.
Past rulings and common cases
Some noteworthy cases in which web scraping is illegal and that you should be aware of include individuals or companies abusing web scraping and violating Terms of Service or copyright norms.
📌 Ruling by the US Ninth Circuit of Appeals Court – LinkedIn vs. HiQ
LinkedIn brought a battle in order to stop a competitor, HiQ, from scraping personal information from users’ LinkedIn public profiles.
In 2020, the ruling established that the CFAA was not violated since the data scraped from LinkedIn was public (not behind a password wall).
📌 Clearview AI Fine
The facial recognition firm earned a heavy fine for scraping millions of pictures of people’s faces from social media.
It was declared that Clearview AI was processing sensitive data without a valid legal basis. Read the full story on our blog.
What you need to do
As a web scraper
✅ Be careful if downloading data from a website that requires you to log in, as this could mean that you have agreed to Terms of Service which may forbid web scraping activities.
✅ Make sure to check the website’s Terms and Conditions to ensure you’re not in breach of contract.
✅ Even if it’s publicly available data, make sure data isn’t protected by copyright. This can include articles, videos, designs.
✅ Lastly, and most importantly, consider the ethics involved. Even if an activity isn’t illegal, it can still cause harm or reputational damage to you or others.
As a website owner
To protect your website from having its information scraped, you can:
🔒 Copyright your website and write a copyright clause;
🔒 You should add web scraping restrictions to your website’s Terms and Conditions document. When doing so, make sure language is specific and forbid third parties from scraping information and use it for commercial purposes, for example.
👋 Here’s how to easily do this with iubenda software solutions:
🚀 Use iubenda’s Terms and Conditions Generator;
🚀 Create your customized Terms and Conditions document;
🚀create a custom clause or select our pre-drafted clauses including content rights clauses;
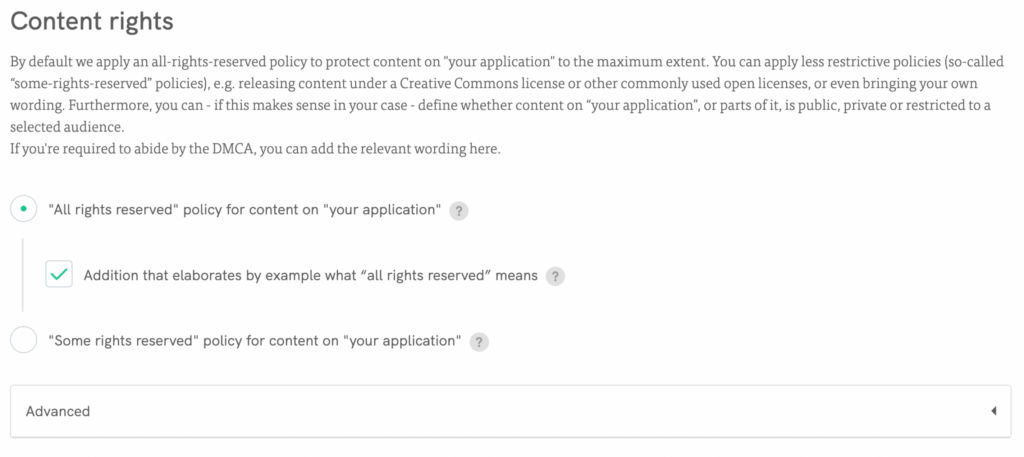
🚀 Easily add anti-scraping clause: Acceptable use → Personalized acceptable use clause (list with specific statements for acceptable/forbidden uses, going deep with examples and statements) → Add a list with scraping restrictions
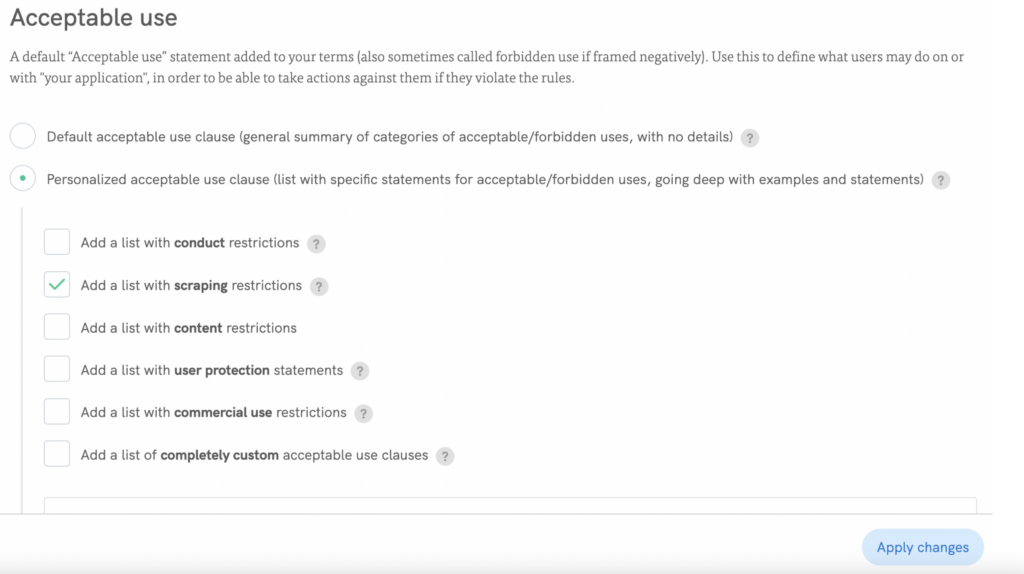
🚀 Follow our instructions to quickly install the document on your website!
About us

Attorney-level solutions to make your websites and apps compliant with the law across multiple countries and legislations.