Le « web scraping » est l’une des méthodes de collecte de données les plus courantes, mais sa légalité fait encore l’objet de nombreux débats. Le web scraping est-il légal? Bien que la réponse ne soit pas si simple, nous examinons dans ce billet ce qu’est le web scraping, ses implications juridiques et les meilleures pratiques. 👀 Plongeons dans le vif du sujet !

Qu’est-ce que le web scraping ?
Web scraping (ou grattage de données) : qu’est-ce que c’est et comment ça marche ?
Le web scraping consiste à extraire des données d’un site web. Les informations collectées sont ensuite exportées dans un format plus utile pour l’utilisateur.
En termes plus techniques, le scraper utilise le code/les éléments HTML, CSS ou JavaScript d’une page web et extrait toutes les données présentes ou sélectionne certaines informations spécifiques de valeur. En fait, le web scraping vous permet de cibler des informations spécifiques (par exemple, vous pouvez rechercher les prix sur une page Amazon, mais pas les commentaires sur les produits).
🔍 En général, le web scraping est réalisé à l’aide d’outils dédiés et automatisés qui fonctionnent plus rapidement que le web scraping manuel.
Exemples de grattage de sites web
Bien que le web scraping implique des développeurs car il peut être assez technique, il s’agit d’un outil précieux pour les chercheurs, les journalistes, les universitaires et bien d’autres.
Le web scraping peut être utilisé pour :
- Étude de marché (c’est-à-dire analyse de la concurrence sur les données relatives aux produits provenant de sites de commerce électronique tels qu’Amazon ou eBay) ;
- Surveillance des prix (c’est-à-dire des cours boursiers) ;
- Suivi de l’actualité;
- Rassembler des localisateurs de magasins, des statistiques sportives, etc.
Le web scraping est-il légal ?
La légalité du web scraping
Comme la plupart des personnes qui font des recherches sur ce sujet, vous vous demandez peut-être si le scraping de données est légal. Ne soyez pas trop enthousiaste, malheureusement, tout le sujet reste une zone grise.
Le « web scraping » est généralement autorisé dans les cas suivants
- les données extraites sont des données publiques; et
- les informations collectées ne sont pas protégées par un login.
En règle générale, un « web scraping » responsable exige que vous fassiez preuve de prudence en ce qui concerne les conditions de service applicables, les données protégées par le droit d’auteur et les données personnelles (les données personnelles étant généralement protégées par les lois sur la protection de la vie privée).
🔍 Consultez notre guide détaillé sur ce qui est considéré comme des informations personnelles dans les principales lois sur la protection de la vie privée.
Le scraping de données dans le cadre de la législation sur la protection de la vie privée
Les principales lois sur la protection de la vie privée adoptées à ce jour dans l’UE (le GDPR) ou aux États-Unis (le CPRA) visent à protéger les données personnelles des utilisateurs et à définir un cadre pour l’utilisation de ces données.
Ils ne font pas référence au « web scraping » et n’indiquent pas qu’il s’agit d’une pratique illégale. Cependant, elles réglementent la collecte de données personnelles par les entreprises et ce qu’elles peuvent en faire. En bref – car oui, la loi est bien plus compliquée que cela ! – il s’agit généralement de
- recevoir le consentement explicite des personnes concernées ;
- recueillir des données à caractère personnel uniquement à des fins spécifiques;
- informer les utilisateurs de la nature des données collectées, de la manière dont elles sont collectées et de leurs droits.
🔍 En résumé, si vos activités de web scraping impliquent la collecte d’informations personnelles, vous devez vous assurer que vous êtes en conformité avec les lois sur la protection de la vie privée.
💡 Vous ne savez pas quelles sont les lois sur la protection de la vie privée qui s’appliquent à vous ?
Garantie d’orientation
Veuillez noter que bien que ces conseils proviennent de la Garante italienne, les suggestions sont utiles pour tous les pays.
En mai 2024, la Garante a publié un document d’orientation qui contient des instructions pour défendre les données à caractère personnel publiées en ligne par des entités publiques et privées en tant que responsables du traitement des données contre le grattage sur le web dans le contexte de la formation à l’IA générative. La Garante propose un certain nombre de mesures concrètes à adopter, notamment
- la création de zones réservées, accessibles uniquement sur inscription, afin de soustraire les données à la disponibilité du public ;
- l’inclusion de clauses anti-scraping dans les conditions de service des sites web ou des plateformes en ligne ;
- la surveillance du trafic vers les pages web, afin d’identifier tout flux anormal de données entrantes et sortantes (un exemple de mesure appropriée consiste à limiter le trafic réseau et le nombre de demandes d’accès en ne sélectionnant que celles provenant de certaines adresses IP) ; et
- la mise en œuvre de mesures spécifiques contre les robots à l’aide de certaines solutions technologiques (par exemple : intervenir sur le fichier robots.txt ; inclure des contrôles CAPTCHA ; apporter des modifications périodiques au balisage HTML ; incorporer du contenu ou des données destinées à éviter les activités de scraping dans des éléments multimédias tels que des images).
En adoptant ces mesures, bien qu’elles ne soient pas exhaustives en termes de méthode ou de résultat, les exploitants de sites web et de plateformes en ligne peuvent contenir les effets du « scraping » visant à former des algorithmes d’intelligence artificielle générative.
Arrêts antérieurs et cas courants
Parmi les cas notables dans lesquels le web scraping est illégal et que vous devez connaître, on peut citer les individus ou les entreprises qui abusent du web scraping et qui violent les conditions d’utilisation ou les normes en matière de droits d’auteur.
📌 Décision de la Cour d’appel du neuvième circuit des États-Unis – LinkedIn vs. HiQ
LinkedIn a intenté une action en justice pour empêcher un concurrent, HiQ, d’extraire des informations personnelles des profils publics des utilisateurs de LinkedIn.
En 2020, le jugement a établi que la CFAA n’avait pas été violée puisque les données extraites de LinkedIn étaient publiques (et non protégées par un mot de passe).
Clearview AI Fine
La société spécialisée dans la reconnaissance faciale a été condamnée à une lourde amende pour avoir récupéré des millions de photos de visages sur les réseaux sociaux.
Il a été déclaré que Clearview AI traitait des données sensibles sans base juridique valable. Lisez l’article complet sur notre blog.
Ce que vous devez faire
En tant que scraper web
Soyez prudent si vous téléchargez des données à partir d’un site web qui exige que vous vous connectiez, car cela peut signifier que vous avez accepté des conditions de service qui peuvent interdire les activités de « web scraping ».
✅ Vérifiez les conditions générales du site web pour vous assurer que vous n’êtes pas en situation de rupture de contrat.
✅ Même s’il s’agit de données accessibles au public, assurez-vous qu’elles ne sont pas protégées par des droits d’auteur. Il peut s’agir d’articles, de vidéos, de dessins.
Enfin, et surtout, tenez compte de l’éthique. Même si une activité n’est pas illégale, elle peut néanmoins vous porter préjudice ou nuire à votre réputation ou à celle d’autres personnes.
En tant que propriétaire de site web
Pour protéger votre site web contre le piratage de ses informations, vous pouvez.. :
🔒 Protégez votre site web par un droit d’auteur et rédigez une clause de copyright;
🔒 Vous devriez ajouter des restrictions concernant le web scraping dans les conditions générales de votre site web. Dans ce cas, veillez à ce que le libellé soit précis et interdisez aux tiers de récupérer les informations et de les utiliser à des fins commerciales, par exemple.
👋 Voici comment y parvenir facilement avec les solutions logicielles iubenda :
🚀 Utilisez le Générateur de Conditions Générales d’iubenda ;
🚀 Créez votre document de conditions générales personnalisé ;
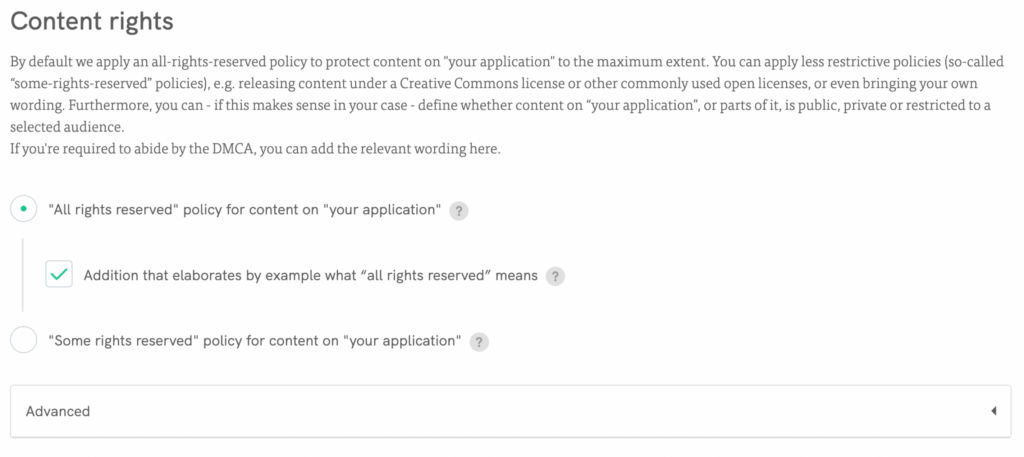
🚀créerune clause personnalisée ou sélectionner nos clauses prérédigées, y compris les clauses relatives aux droits de contenu;
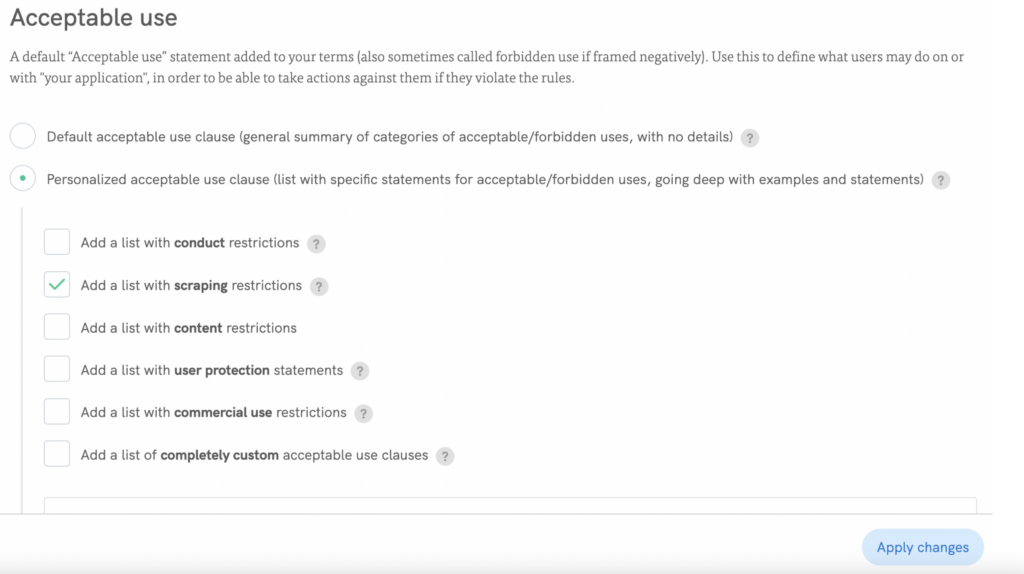
🚀 Ajoutez facilement une clause anti-écrasement: Utilisation acceptable → Clause d’utilisation acceptable personnalisée (liste avec des déclarations spécifiques pour les utilisations acceptables/interdites, avec des exemples et des déclarations détaillées) → Ajouter une liste avec des restrictions sur le scraping
🚀 Suivez nos instructions pour installer rapidement le document sur votre site web !
About us

Attorney-level solutions to make your websites and apps compliant with the law across multiple countries and legislations.