Il web scraping è uno dei metodi di raccolta dati più comuni, ma la sua legalità è ancora una questione molto discussa. Ma allora il web scraping è legale? La risposta non è così semplice: in questo post scopriremo cos’è il web scraping, quali sono le sue implicazioni legali e le best practice. 👀 Iniziamo subito!

Cos’è il web scraping?
Il web scraping (o scraping di dati): cos’è e come funziona
Il web scraping prevede l’estrazione di dati da un sito web: le informazioni raccolte vengono poi esportate in un formato più utile per l’utente.
In termini più tecnici, lo scraper utilizza il codice/elementi HTML, CSS o JavaScript di una pagina web ed estrae tutti i dati presenti o seleziona alcune informazioni specifiche di valore. Infatti, il web scraping consente di concentrasi su determinate informazioni specifiche (ad es. tratta i prezzi di una pagina Amazon ma non le recensioni dei prodotti).
🔍 In generale, il web scraping viene eseguito tramite strumenti dedicati e automatizzati che funzionano più velocemente rispetto al web scraping manuale.
Esempi di web scraping
Sebbene il web scraping coinvolga gli sviluppatori perché può arrivare a livelli piuttosto tecnici, è uno strumento prezioso per ricercatori, giornalisti, accademici e altre figure ancora.
Il web scraping può essere utilizzato per:
- ricerche di mercato (ossia analisi dei concorrenti sui dati dei prodotti provenienti da siti di e-commerce come Amazon o eBay);
- monitoraggio dei prezzi (ad es. prezzi delle azioni);
- monitoraggio delle notizie;
- raccolta di store locator, statistiche sportive, ecc.
Il web scraping è legale?
La legalità del web scraping
Proprio come la maggior parte delle persone che si interessano a questo argomento, potresti chiederti: lo scraping dei dati è legale? Non farti prendere da facili entusiasmi, purtroppo tutta la questione resta in un’area grigia.
Il web scraping è generalmente consentito quando:
- i dati estratti sono dati pubblicamente disponibili; e
- le informazioni raccolte non sono protette da un login.
In generale, il web scraping responsabile richiede prudenza circa i Termini di Servizio, i dati protetti da copyright e i dati personali applicabili (visto che i dati personali di solito sono protetti dalle leggi sulla privacy).
🔍 Consulta la nostra guida dettagliata su cosa è considerato informazione personale nelle principali leggi sulla privacy.
Scraping di dati secondo le leggi sulla privacy
Le principali leggi sulla privacy attualmente in vigore nell’UE (il GDPR) o negli Stati Uniti (il CPRA) mirano a proteggere i dati personali degli utenti e a stabilire un quadro per le modalità di utilizzo di questi dati.
Non fanno riferimento al web scraping, né specificano che sia illegale. Tuttavia, disciplinano la raccolta di dati personali da parte delle aziende e cosa queste ultime possono farne. In sintesi(perché sì, la legge è molto più complicata di così!), di solito è previsto che:
- si riceva il consenso esplicito degli interessati;
- i dati personali vengano raccolti solo per finalità specifiche;
- si informino gli utenti circa quali dati vengono raccolti, in che modo e quali sono i loro diritti.
🔍 In breve, se le tue attività di web scraping comportano lo scraping di informazioni personali, devi assicurarti di essere conforme alle leggi sulla privacy dei dati.
💡 Non sai bene quali leggi sulla privacy si applichino di fatto nel tuo caso?
🚀 Fai questo quiz gratuito di appena 1 minuto per scoprirlo!
Guida Garante
Tieni presente che, sebbene questa guida provenga dal Garante italiano, i suggerimenti sono utili per tutti i Paesi.
Nel maggio 2024, il Garante ha pubblicato un documento di orientamento che contiene le istruzioni per difendere i dati personali pubblicati online da soggetti pubblici e privati in qualità di titolari del trattamento dal web scraping nel contesto dell’addestramento dell’IA generativa. Il Garante suggerisce una serie di misure concrete da adottare, tra cui:
- la creazione di aree riservate, accessibili solo previa registrazione, in modo da sottrarre i dati alla disponibilità pubblica;
- l’inserimento di clausole anti-scraping nei termini di servizio di siti web o piattaforme online;
- il monitoraggio del traffico verso le pagine web, in modo da identificare eventuali flussi anomali di dati in entrata e in uscita (un esempio di misura appropriata da adottare è la limitazione del traffico di rete e del numero di richieste di accesso selezionando solo quelle provenienti da determinati indirizzi IP); e
- l’implementazione di misure specifiche contro i bot utilizzando alcune soluzioni tecnologiche (ad esempio: intervenire sul file robots.txt; includere controlli CAPTCHA; apportare modifiche periodiche al markup HTML; incorporare contenuti o dati volti a evitare attività di scraping all’interno di elementi multimediali come le immagini).
Attraverso l’adozione di queste azioni, sebbene non siano esaustive né nel metodo né nel risultato, i gestori di siti web e piattaforme online possono contenere gli effetti dello scraping finalizzato all’addestramento di algoritmi di intelligenza artificiale generativa.
Sentenze precedenti e casi comuni
Alcuni casi degni di nota secondo cui il web scraping è illegale e di cui dovresti tener conto riguardano persone o aziende che abusano del web scraping e violano i Termini di Servizio o le norme sul copyright.
📌 Sentenza della Corte d’Appello della Nona Circoscrizione degli Stati Uniti: LinkedIn contro HiQ
LinkedIn ha intentato causa per impedire a un concorrente, HiQ, di eseguire lo scraping di informazioni personali dai profili pubblici LinkedIn degli utenti.
Nel 2020, la sentenza ha stabilito che la legge CFAA non era stata violata perché i dati di LinkedIn oggetto di scraping erano pubblici (non protetti da password).
📌 Multa per Clearview AI
L’azienda di riconoscimento facciale ha ricevuto una pesante multa per aver eseguito lo scraping di milioni di foto di volti di persone presi dai social media.
È stato sancito che Clearview AI trattava dati sensibili senza una base giuridica valida. Leggi la storia completa sul nostro blog.
Cosa devi fare tu
In veste di web scraper
✅ Fai attenzione se scarichi dati da un sito web che richiede di eseguire il login, perché ciò potrebbe significare che hai accettato i Termini di Servizio che potrebbero vietare le attività di web scraping.
✅ Assicurati di controllare i Termini e Condizioni del sito web per accertarti di non violarlo.
✅ Anche se si tratta di dati pubblicamente disponibili, assicurati che i dati non siano protetti da copyright. Questa protezione può riguardare articoli, video e disegni.
✅ Infine, e soprattutto, considera la questione etica. Anche se un’attività non è illegale, può comunque causare danni di fatto o danni alla reputazione a te o ad altri.
In veste di titolare di un sito web
Per proteggere il tuo sito web dallo scraping di informazioni, puoi:
🔒 Tutelare i diritti d’autore del tuo sito web e scrivere una clausola di copyright;
🔒 Aggiungere delle restrizioni relative al web scraping al documento Termini e Condizioni del tuo sito web. Quando lo fai, assicurati che il linguaggio sia specifico e vieta a terzi di eseguire lo scraping di informazioni e di usarle per scopi commerciali, per esempio.
👋 Ecco come farlo facilmente con le soluzioni software iubenda:
🚀 Usa il Generatore di Termini e Condizioni di iubenda;
🚀 Crea il tuo documento di Termini e Condizioni personalizzato;
🚀 Creauna clausola personalizzata o seleziona le nostre clausole preconfezionate, comprese quelle relative ai diritti sui contenuti;
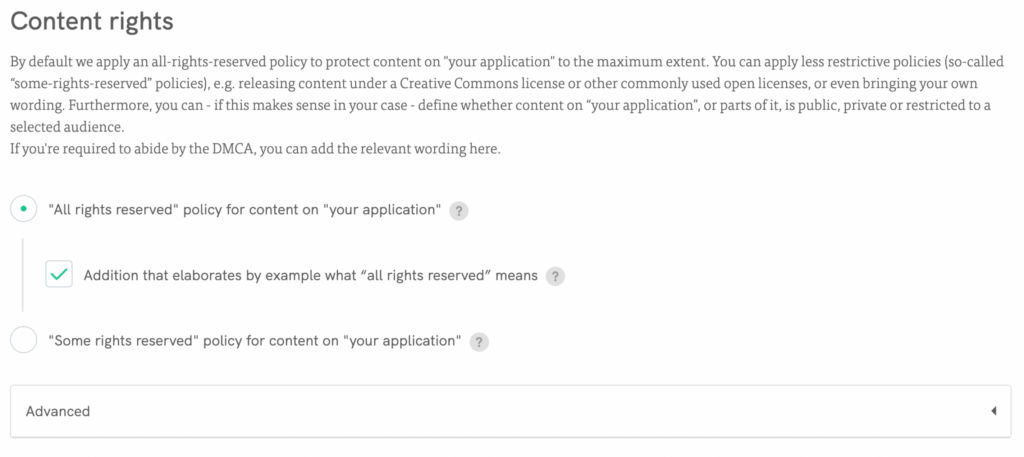
🚀 Aggiungi facilmente una clausola anti-scraping: Uso accettabile → Clausola di uso accettabile personalizzata (elenco con dichiarazioni specifiche per gli usi accettabili/vietati, approfondendo con esempi e dichiarazioni) → Aggiungi un elenco con le restrizioni allo scraping
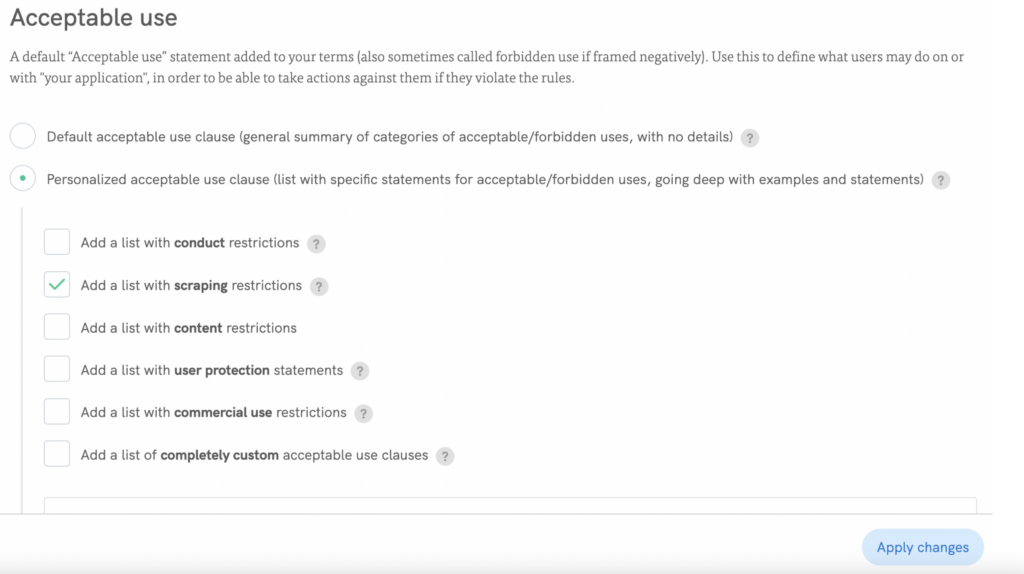
🚀 Segui le nostre istruzioni per installare rapidamente il documento sul tuo sito web!
Chi siamo

Soluzioni pensate da un team di avvocati per adeguare i tuoi siti web e le tue app alle normative di più Paesi e legislazioni